Markov Decision Processes
Contents
Markov Decision Processes¶
Warning
Please note that this notebook is still work in progress, hence some sections could behave unexpectedly, or provide incorrect information.
As discussed in The Reinforcement Learning Problem, fully observable environments in Reinforcement Learning have the Markov property. This means the environment can be represented by a Markov Decision Process (MDP). This means that the current state completely characterizes the process. MDPs are very important in RL, since they can represent almost every problem.
From Markov Chains to Markov Decision Processes¶
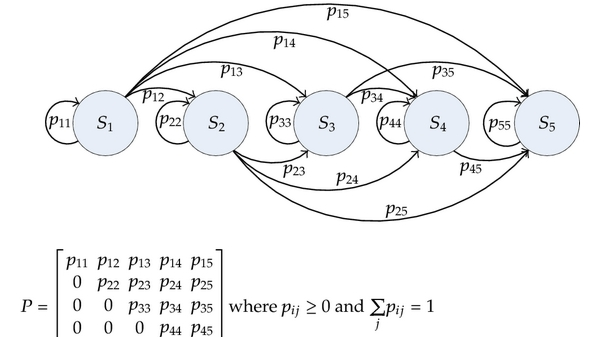
Fig. 1 Example of a Markov Chain¶
Here, \(P\) is the Transition Matrix. It contains all transition probabilities of the model. A Markov Chain (or Markov Process), is a tuple \((S, P)\), where \(S\) is a set of states and \(P\) is the transition matrix. A sequence \(S_0, ..., S_n\) is called an episode.
From this Markov Chain, we can create a Markov Reward Process. This is defined as an extension of the tuple, with the elements \((S, P, R, \gamma)\). \(S\) and \(P\) mean the same thing as before. However, now we also have a reward function and a discount factor \(\gamma \in [0, 1]\). One can create such a reward function by adding reward values to each state in the markov chain.
Now let’s introduce the Bellman Equation for MRPs. It is possible to rewrite the formula of the value function in the following way.
Equation (1) shows the bellman equation of the value function in a markov reward process.
Now it is possible to see that the value of a state is dependent on the immediate reward, and the return of neighboring states. This can then be computed using the transition matrix (\(P_{ss'} > 0 \iff\) you can go from \(s\) to \(s'\)). The bellman equation can then be written in matrix form, namely \(v = R + \gamma Pv\). This can be rewritten as \(v = (I - \gamma P)^{-1} R\). This equation can be solved in \(O(n^3)\), since a matrix inverse is necessary. For large MRPs, there are several iterative methods to solve this equation. For example,
Dynamic programming
Monte-Carlo evaluation
Temporal-Difference learning
These methods will be explained in later chapters.
Markov Decision Processes¶
Finally, let’s talk about the Markov Decision Process. This is an extension of the MRP, with properties \((S, A, P, R, \gamma)\). It introduces a new set, defining the actions that can be taken. The transition matrix \(P^a\) and \(R^a\) now also conditionally depend on the action.
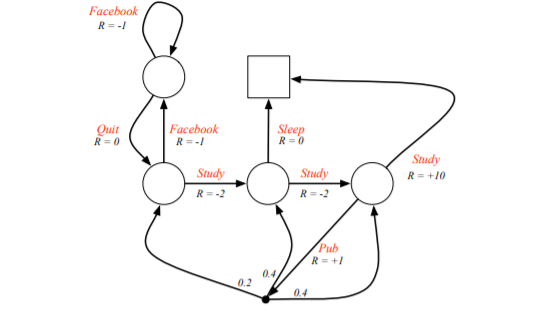
Fig. 2 Example of a Markov Decision Process¶
Fig. 2 is an example of a Markov Decision Process. In the image you see that the rewards are now dependent on the actions, as previously explained. Now it is possible to talk about the behavior of an agent. In chapter 1, policies were mentioned. These determine the behavior of agents (like which action to take in which state).
Given an MDP and a policy \(\pi\). The state sequence \(S_0, S_1, ...\) is a Markov Process \((S, P^\pi)\) and the state and reward sequence \(S_0, R_1, S_1, R_2, ...\) is a Markov Reward Process \((S, P^\pi, R^\pi, \gamma)\) where \(P^\pi_{s, s'} = \sum_{a \in A} \pi(a | s)P^a_{s, s'}\) and \(R^\pi_s = \sum_{a \in A} \pi(a | s)R^a_s\) (Law of Total Probability).
Similarly to the state-value function \(v_\pi(s)\), let’s now define the action-value function \(q_\pi(s, a) = \mathbb{E}_\pi[G_t | S = s, A = a]\). This is the expected return starting from state \(s\), taking action \(a\), and then following policy \(\pi\). In a RL problem, this is what we care about. The goal is to select the best action in a given state, in order to maximize the reward. If we have access to the \(q\)-values, it is the solution to the problem.
After deriving the Bellman equations for the MDPs, we end up with the following formulas.
Equation (2) shows the bellman equation of the state value function in a markov decision process. There is an equivalent definition, which expresses the bellman equation in terms of the state-action value pairs, instead of the state value function.
Equation (3) shows the bellman equation of the state-action value function in a markov decision process.
The second-last form of the equation can be intuitively thought of as the following. Imagine we are taking a certain action in a state. Then, the environment might bring us into different successor states even if we take the action. So, we have to sum over all these possible successor states and use the law of total probability again to compute the action-values.
Now we can talk about optimality. The optimal state-value and optimal action-value functions are defined as \(v_*(s) = \max_\pi v_\pi(s)\) and \(q_*(s, a) = \max_\pi q_\pi(s, a)\). We can say \(\pi \geq \pi'\) if \(\forall s: v_\pi(s) \geq v_{\pi'}(s)\). The optimal value function specifies the best possible performance in the MDP. An MDP is “solved” when we know the optimal value. For any MDP, there always exist an optimal policy that is better or equal to all policies. This policy achieves both the optimal value function and the optimal action-value function.
An optimal policy can be found by maximizing over \(q_*(s, a)\).
Equation (4) shows the formulation of an optimal policy in a markov decision process.
The optimal value functions are recursively related to the Bellman Optimality Equations. \(v_*(s) = \max_a q_*(s, a)\) and \(q_*(s, a) = R^a_s + \gamma \sum_{s' \in S} P^a_{ss'}v_*(s')\). Solving for these equations is difficult, since the Bellman Optimality Equation is non-linear. Generally, there is no closed form solution. However, there exist iterative methods to approximate the solution. Example of this are
Value Iteration
Policy Iteration
Q-learning
SARSA
Extensions to MDPs (advanced)¶
Infinite and continuous MDPs¶
Countably infinite state and/or action spaces
Straightforward
Continuous state and/or action spaces
Closed form for linear quadratic model (LQR)
Continuous time
Requires partial differential equations
Hamilton-Jacobi-Bellman (HJB) equation
Limiting case of Bellman equation as the time-step approaches 0
Partially observable MDPs¶
A Partially Observable Markov Decision Process is an MDP with hidden states. It is a hidden Markov model with actions. A POMDP is a tuple \((S, A, O, P, R, Z, \gamma)\). We now also have \(O\) representing a finite state of observations and \(Z\) being an observation function \(Z^a_{s'o} = \mathbb{P}[O_{t+1} = o | S_{t+1} = s', A_t = a]\).
Let’s define a history \(H_t\) being a sequence of actions, observations and rewards (\(H_t = A_0, O_1, R_1, ..., A_{t-1}, O_t, R_t\)). A belief state \(b(h)\) is a probability distribution over states conditioned on the history h. \(b(h) = (\mathbb{P}[S_t = s^1 | H_t = h], ..., \mathbb{P}[S_t = s^n | H_t = h])\).The history and belief state both satisfy the Markov property. A POMDP can be reduced to an (infinite) history tree and an (infinite) belief state tree.