Exploration and Exploitation
Contents
Exploration and Exploitation¶
Warning
Please note that this notebook is still work in progress, hence some sections could behave unexpectedly, or provide incorrect information.
The trade-off between exploration and exploitation is a fundamental problem in Reinforcement Learning and online decision-making. It provides a trade-off between making a decision based on the current beliefs, or gather more of this information.
In general, the long-term is preferred over short-turn. This means the best strategy might include short-term sacrifices . The foal is to gather enough information to make the best overall decisions.
This chapter will first explain exploration in a special forms of an MDP, called bandit problems. Finally, these ideas are generalized to the general MDP.
There are lots of principles to make sure to explore. There include but are not limited to the following
Naive Exploration: Add noise to greedy policy (e.g. \(\epsilon\)-greedy)
Optimistic Initialization: Assume the best until proven otherwise
Optimism in the face of uncertainty: Prefer actions with uncertain values
Probability Matching: Select actions based on probability their are best
Information State Search: Look-ahead search incorporating value of information
Multi-Armed Bandits¶
A multi-armed bandit is a tuple \((A, R)\). Here, \(A\) is a known set of actions (arms) and \(R^a(r) = \mathbb{P}\left[r | a\right]\) is an unknown probability distribution over rewards. At each step \(t\), the agent chooses an action \(a_t \in A\). Then, the environment generates a reward \(r_t \sim R^{a_t}\). The goal is to maximize the cumulative reward \(\sum_{T = 1}^{t} r_T\).
The goal is to maximize this reward. However, this can otherwise be states as minimizing the total regret. The action-value is the expected reward of an action (\(Q(a) = \mathbb{E}\left[r | a\right]\)). The optimal value \(V* = Q(a^*) = \max_{a \in A} Q(a)\).
The regret is the measured opportunity loss for one step: \(l_t = \mathbb{E}\left[V^* - Q(a_t)\right]\). The total regret is then equal to the total opportunity loss \(L_t = \mathbb{E}\left[\sum_{T = 1}^{t} V^* - Q(a_t)\right]\).
It is possible to count regret. The count \(N_t(a)\) is the expected number of selection for action \(a\). For that action, there is a gap in difference of value between \(a\) and \(a^*\). This gap equals \(\Delta_a = V^* - Q(a)\). The regret can then be rewritten to the following
So, the regret is a function of the gaps and counts. A good algorithm will ensure small counts for large gaps. There is a problem however; the gaps are not known.
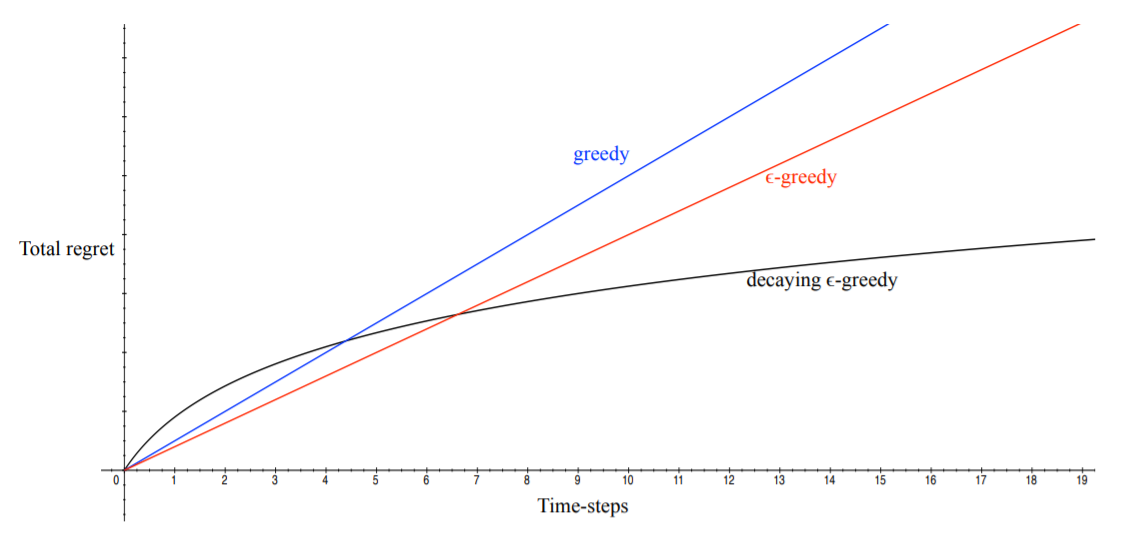
Fig. 9 Total regret over time¶
From Fig. 9, the following observations can be made. If an algorithm never- or forever explores, the total regret will be linear. This is not good, since the goal is to minimize regret while exploring. The idea of decaying \(\epsilon\)-greedy is interesting, since it will converge to a logarithmic regret.
Lets estimate \(Q(a) \approx \hat{Q}_t(a)\). The value of each action can be evaluated by MC-evaluation: \(\hat{Q}_t(a) = \frac{1}{N_t(a)} \sum_{t = 1}^{T} r_t 1(a_t = a)\).
Since the greedy algorithm always selects the action with the highest value, it can lock onto a sub-optimal action forever, thus receiving a linear total regret.
Using an \(\epsilon\)-greedy algorithm, the constant \(\epsilon\) ensures that the minimum regret \(l_t \geq \frac{\epsilon}{A} \sum_{a \in A} \Delta_a\). Thus, the total regret is also linear.
A simple but powerful idea is to use Optimistic Initialization. Initialize \(Q(a)\) to a very high value and from there on update the action-value by MC evaluation starting with \(N(a) > 0\). It encourages exploration early on, but can still lock onto sub-optimal actions. In practice however, this generally works really well.
The decaying \(\epsilon\)-greedy algorithm works by picking a decaying schedule for \(\epsilon_1, \epsilon_2, ...\) . Imagine the following schedule
There is a problem with the schedule though. It uses advance knowledge about gaps. So, the goal is to find an algorithm with sub-linear regret for any multi-armed bandit without using knowledge of \(R\).
The performance of any algorithm is determined by the similarity between the optimal arm and other arms. Hard problem have similar-looking arms with different means. This can be described as the size of the gap, and the similarity in distributions (measure by KL-divergence).
The following Lower Bound is a theorem. It means the asymptotic total regret is at least logarithmic in the number of steps.
Upper Confidence Bounds¶
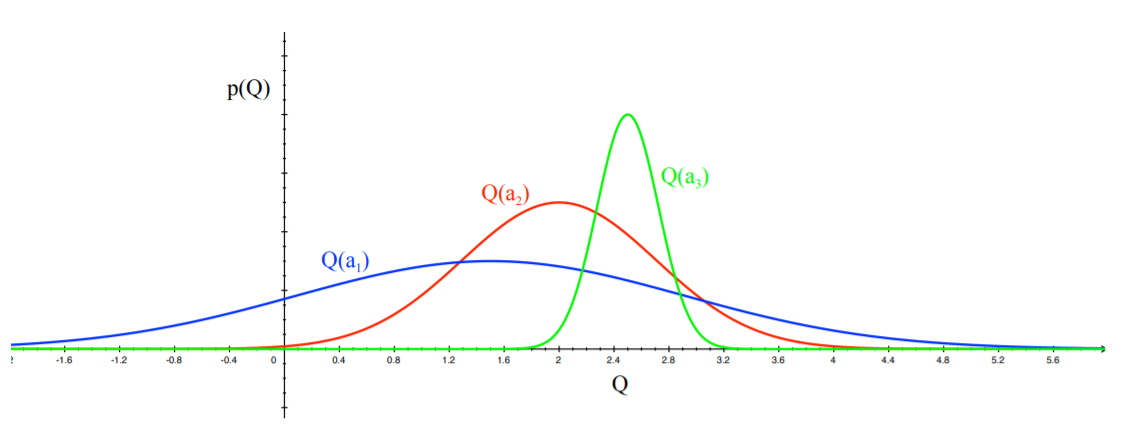
Take a look at the figure above. The idea of Optimism in the Face of Uncertainty is to pick the action with the highest potential. This would be \(a_1\), since the tail of the distribution is the best one of them all. Say you pick this action. Then, the distribution gets updated.
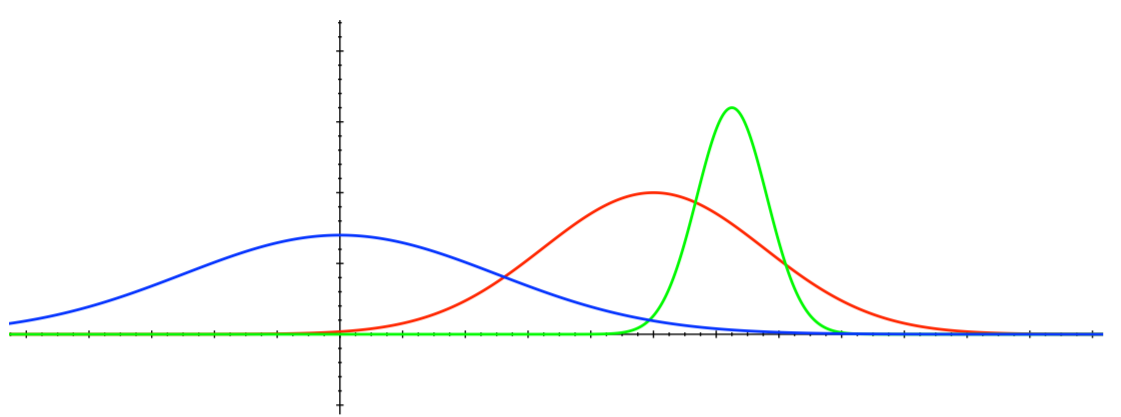
Now, we are more certain about the actual value of \(Q(a_1)\) and thus more likely to pick another action until the optimal one has been discovered.
Another way to estimate uncertainty is through Upper Confidence Bounds (UCB). An upper confidence \(\hat{U}_t(a)\) can be calculated for each action-value, such that \(Q(a) \leq \hat{Q}_t(a) + \hat{U}_t(a)\) with high probability. The action maximizing the UCB is then selected.
By Hoeffding’s Inequality, \(\mathbb{P}\left[\mathbb{E}\left[X\right] > \bar{X}_t + u\right] \leq e^{-2tu^2}\) for \(\bar{X}_t = \frac{1}{T} \sum_{t = 1}^T X_t\), where \(X_t\) is an i.i.d. r.v. in \([0, 1]\). When applying this to the bandit problem, the following can be derived
Now, pick a probability \(p\) that the true value exceeds the UCB.
Since the goal is to reduce the probability as more rewards are observed, set e.g. \(p = t^{-4}\). Then ensures the optimal action is selected when \(t \rightarrow \infty\). The final equation becomes
This leads to the UCB1 algorithm
Theorem: the UCB algorithm achieves logarithmic asymptotic total regret
Bayesian Bandits¶
So far, no assumptions were made about the reward distribution \(R\), except for bounds on rewards. Bayesian Bandits exploit prior knowledge of rewards, \(p\left[R\right]\). They compute the posterior distribution of reward \(p\left[R | h_t\right]\), where \(h_t = a_1, r_1, ..., a_{t-1}, r_{t-1}\) is the history. The posterior distribution can then be used to guide exploration.
The following is an example. Assume that the reward distribution is Gaussian, so \(R_a(r) = N(r; \mu_a, \sigma_a^2)\). The Gaussian posterior over \(\mu_a\) and \(\sigma_a^2\) can be computed using Bayes’ law: \(p[\mu_a, \sigma_a^2; h_t] \propto p[\mu_a, \sigma_a^2] \prod_{t | a_t = a} N(r_t; \mu_a, \sigma_a^2)\).
Then, pick the action that maximizes the standard deviation of \(Q(a)\), so \(a_t = \arg\max_{a \in A} \mu_a + \frac{c \sigma_a}{\sqrt{N(a)}}\). This is a Bayesian way to compute Upper Confidence Bounds.
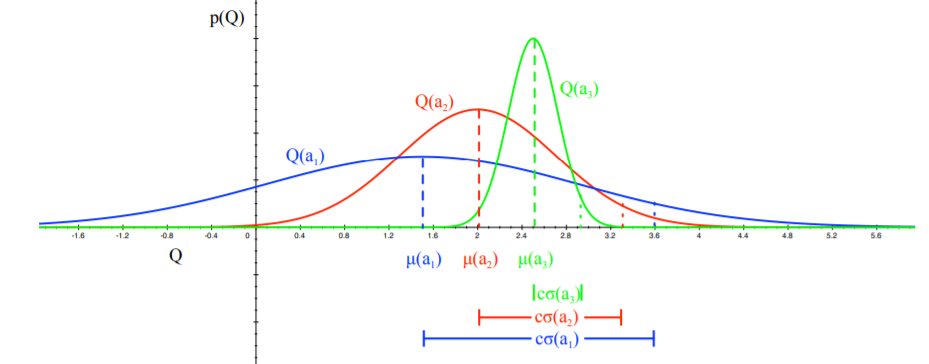
Here, the blue action would be taken. This is because the mean and standard deviation summed up is the largest (assuming an equal number of visits).
Probability Matching¶
Probability Matching selects an action \(a\) according to the probability that \(a\) is optimal. It can be calculated using
This concept is optimistic in the face of uncertainty, since uncertain actions have a higher probability of being the maximum. A disadvantage however is that it can be difficult to be computed analytically from the posterior.
Thompson Sampling is sample-based probability matching. The policy can be computed using
Then, use Bayes’ law to compute the posterior distribution \(P_w(Q|R_1, ..., R_{t-1})\). First sample an action-value \(Q(a)\) from the posterior. Then, choose action \(A_t = \arg\max_{a \in A} Q(a)\).
Information State Search¶
The goal of exploration is to gain more information about the environment. If it is possible to quantify how much this information is worth. When this value is known, the optimal trade-off between exploration and exploitation is known.
The idea is to look at bandits as sequential decision-making processes instead of one-step. At each step, there is an information state \(\bar{s} = f(h_t)\). So, the state is a summary of all history that has been accumulated so far. Each action \(a\) then causes a transition to a new information state \(\bar{s}'\), with probability \(\bar{P}^a_{\bar{s}\bar{s}'}\).
This defines the MDP \(\bar{M}\) in augmented information state space \(\bar{M} = (\bar{S}, A, \bar{P}, R, \gamma)\).
An example of this are Bernoulli Bandits, so lets say \(R^a = Bernoulli(\mu_a)\). The goal is to find the arm with the highest \(\mu_a\). The information state space \(\bar{s} = (\alpha, \beta)\), where \(\alpha_a\) and \(\beta_b\) count when the reward was 0 or 1 respectively. This MDP can then be solved by previously discussed Reinforcement Learning algorithms. There is an alternative approach, referred to as Bayes-adaptive RL. For Bernoulli bandits, it finds the Bayes-optimal exploration/exploitation trade-off with respect to the prior distribution.
Imagine a problem of drug assignment. There are two drugs 1 and 2 that can be used; \(\bar{s} = (\alpha_1, \beta_1, \alpha_2, \beta_2)\). First, start with a \(Beta(\alpha_a, \beta_a)\) prior over reward function \(R^a\). Each time \(a\) is selected, the distribution gets updated accordingly, since a success will increase beta , and a failure increases alpha. Here, each state transition corresponds to a Bayesian model update.
The solution of this problem is known as the Gittens index, and can be computed by solving the MDP (by using for example MCTS for planning).
Contextual Bandits¶
A Contextual Bandit is a tuple \((A, S, R)\). Instead of the bandit problem, there is now also a state space, which provides context to the problem. \(S = \mathbb{P}[s]\) is an unknown distribution over the contexts. Then, the reward \(R^a_s(r) = \mathbb{P}[r|s, a]\) is an unknown probability distribution of the rewards. At each time step, the environment generates \(s_t \sim S\). Then, an agent selects \(a_t \in A\), to which the environment generates \(r_t \sim R^{a_t}_{s_t}\). The goal is to maximize \(\sum_{T=1}^t r_T\).
This section explains the concept of Linear UCB. The action-value function needs to be estimated: \(Q(s, a) = \mathbb{E}[r|s,a] \approx Q_\theta(s, a) = x(s, a)^\intercal \theta\). The parameters of this linear function can be estimated by least-squares. The solution is
Least squares regression estimates \(Q_\theta(s, a)\). However, it can also be used to estimate the variance of the action-value \(\sigma^2_\theta(s, a)\). The idea is to add a bonus for uncertainty, \(U_\theta(s, a) = c\sigma\), where the UCB is the number of standard deviations above the mean defined by \(c\).
For least squares regression, parameter covariance is \(A^{-1} = \left(\sum_{T=1}^t x(s_T, a_T)x(s_T, a_T)^\intercal\right)^{-1}\). The action-value is linear in features, so
Markov Decision Processes¶
All previously described principles for exploration/exploitation can apply to MDPs with slights modifications.
Optimistic Initialization
Model-Free RL
The idea is to initialize \(Q(s, a)\) to \(\frac{r_{max}}{1 - \gamma}\). This encourages systematic exploration of states and actions.
Model-Based RL
Here, an optimistic model of the MDP is constructed. For example, transitions to a terminal state are initialized with \(r_{max}\) reward. An example is the RMax algorithm (Brafman and Tennenholtz).
Optimism in the Face of Uncertainty
Model-Free RL
The goal is to maximize UCB on the action-value function \(Q^\pi(s, a)\). \(a_t = \arg\max_{a \in A} Q(s_t, a) + U(s_t, a)\). It estimates uncertainty in policy evaluation. However, it completely ignores uncertainty in the policy improvement step.
For this reason, maximize UCB on \(Q^*(s, a)\) instead. \(a_t = \arg\max_{a \in A} Q(s_t, a) + U_1(s_t, a) + U_2(s_t, a)\). This estimates uncertainty in both policy evaluation and policy improvement. However, estimating policy improvement uncertainty is hard to do.
Model-Based RL
Bayesian Model-Based RL maintains a posterior distribution over MDP models. Both transitions and rewards are estimated \(p[P, R| h_t], h_t = s_1, a_1, r_2, ..., s_t\). This posterior can then be used to guide exploration by for example Bayesian UCB or Thompson Sampling.
Probability Matching
Thompson sampling implements probability matching
\[\begin{split} \pi(s, a | h_t) & = \mathbb{P}[Q^*(s, a) > Q^*(s, a'), \forall a' \neq a | h_t]\\ & = \mathbb{E}_{P, R| h_t}\left[1(a = \arg\max_{a \in A} Q^*(s, a))\right]\end{split}\]Bayes’ Law can be used to compute posterior distribution \(p[P, R| h_t]\). Then, sample an MDP \(P, R\) from the posterior. Then, solve this MDP using a favored planning algorithm to obtain \(Q^*(s, a)\). Then, select the optimal action from the sample MDP by \(a_t \arg\max_{a \in A} Q^*(s_t, a)\).
Information State Search
MDPs can also be augmented to include an information state. The augmented state becomes \((s, \hat{s})\), where \(s\) is the original state within the MDP, and \(\hat{s}\) is accumulated information about the history. Each action \(a\) causes a transition to \(s'\) with probability \(P^a_{ss'}\). However, a new information state \(\hat{s}'\) is also created.
The posterior distribution over the MDP model is an information state \(\hat{s_t} = \mathbb{P}[P, R| h_t]\). An augmented MDP over \((s, \hat{s})\) is called a Bayes-Adaptive MDP.
Solving this MDP gives rise to the optimal exploration/exploitation trade-off. However, the Bayes-Adaptive MDP is typically enormous. Simulation-based search has been proven effective to this problem.