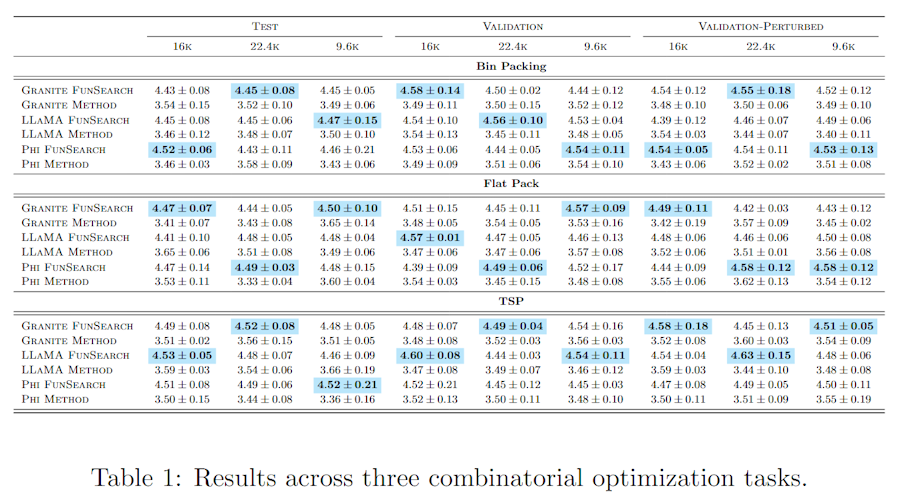
grouped_multicol_latex#
Render a grouped LaTeX table with hierarchical column headers.
The DataFrame must contain:
A row label column (e.g., ‘Model’)
Two columns for column grouping (e.g., ‘Split’, ‘Budget’)
A grouping column for row-wise subtables (e.g., ‘Task’)
A value column, which can be: – a float (e.g., 0.92) – or a list of floats (e.g., [0.91, 0.93, 0.92])
Automatically computes mean ± std or stderr
Highlights best values (min or max) per column within each group
🧾 Required LaTeX packages / commands#
\usepackage{booktabs}\usepackage{scalefnt}\newcommand{\highlightcolor}[1]{\colorbox[HTML]{bae6fb}{\textbf{#1}}}
📥 Arguments#
Name |
Type |
Required |
Description |
|---|---|---|---|
df |
pd.DataFrame |
✅ |
DataFrame with row and column metadata + values. Must include all column names passed below. |
row_index |
str |
✅ |
Name of the column to use for the leftmost index (e.g., ‘Model’). |
col_index |
List[str] |
✅ |
Two column names to create multi-level column headers (e.g., [‘Split’, ‘Budget’]). |
groupby |
str |
✅ |
Column used to group subtables (e.g., ‘Task’). |
value_column |
str |
✅ |
Column containing scalar or list-like values to format. |
highlight |
str |
❌ |
‘min’ or ‘max’ to bold best values per column within each group. |
stderr |
bool |
❌ |
Use standard error instead of std deviation. |
caption |
str |
❌ |
Optional LaTeX caption added below the table. |
label |
str |
❌ |
Optional LaTeX label for referencing. |
📦 Example Output#
Click to show example code
import numpy as np
import pandas as pd
from swizz import table
# Config
tasks = ["Bin Packing", "TSP", "Flat Pack"]
models = ["LLaMA FunSearch", "LLaMA Method", "Phi FunSearch", "Phi Method", "Granite FunSearch", "Granite Method"]
splits = ["Validation", "Validation-Perturbed", "Test"]
budgets = ["9.6k", "16k", "22.4k"]
# Create 4-level MultiIndex
index = pd.MultiIndex.from_product([tasks, models, splits, budgets], names=["Task", "Model", "Split", "Budget"])
# Random generator with slight bias per method
np.random.seed(42)
def simulate_scores(model):
base = {
"FunSearch": 4.5,
"Method": 3.5,
}["Method" if "Method" in model else "FunSearch"]
return [round(np.random.normal(loc=base, scale=0.1), 3) for _ in range(3)]
# Fill DataFrame
data = {"score": [simulate_scores(model) for (_, model, _, _) in index]}
df = pd.DataFrame(data, index=index).reset_index()
latex_code = table(
"grouped_multicol_latex",
df=df,
row_index="Model", # Goes on the left
col_index=["Split", "Budget"], # Becomes multicolumn/multicolumn in header
groupby="Task", # Each task gets a separate subtable section
value_column="score", # List of values to be formatted
highlight="max", # Highlight lowest mean in each column
stderr=False, # Use std error instead of std dev
caption="Results across three combinatorial optimization tasks.",
label="tab:combinatorial_results"
)
print(latex_code)