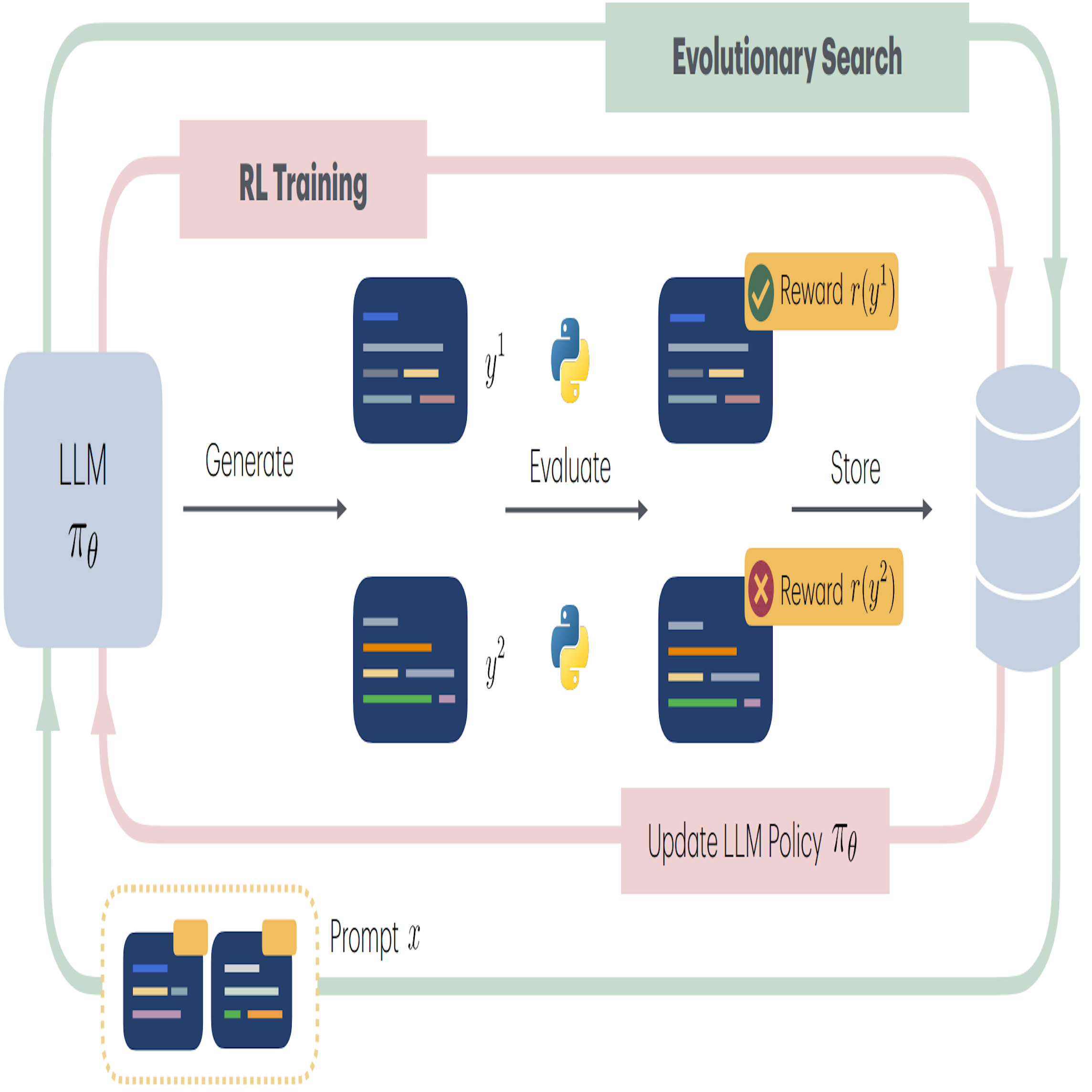
Algorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
COLMAnja Surina , Amin Mansouri , Lars Quaedvlieg , Amal Seddas , Maryna Viazovska , Emmanuel Abbe , Caglar Gulcehre
Conference on Language Modeling (COLM) · 2025
Publications by year in reversed chronological order. Also see my Google Scholar profile.
Anja Surina , Amin Mansouri , Lars Quaedvlieg , Amal Seddas , Maryna Viazovska , Emmanuel Abbe , Caglar Gulcehre
Conference on Language Modeling (COLM) · 2025
Lars Quaedvlieg
arXiv preprint arXiv:2501.19063 · 2025
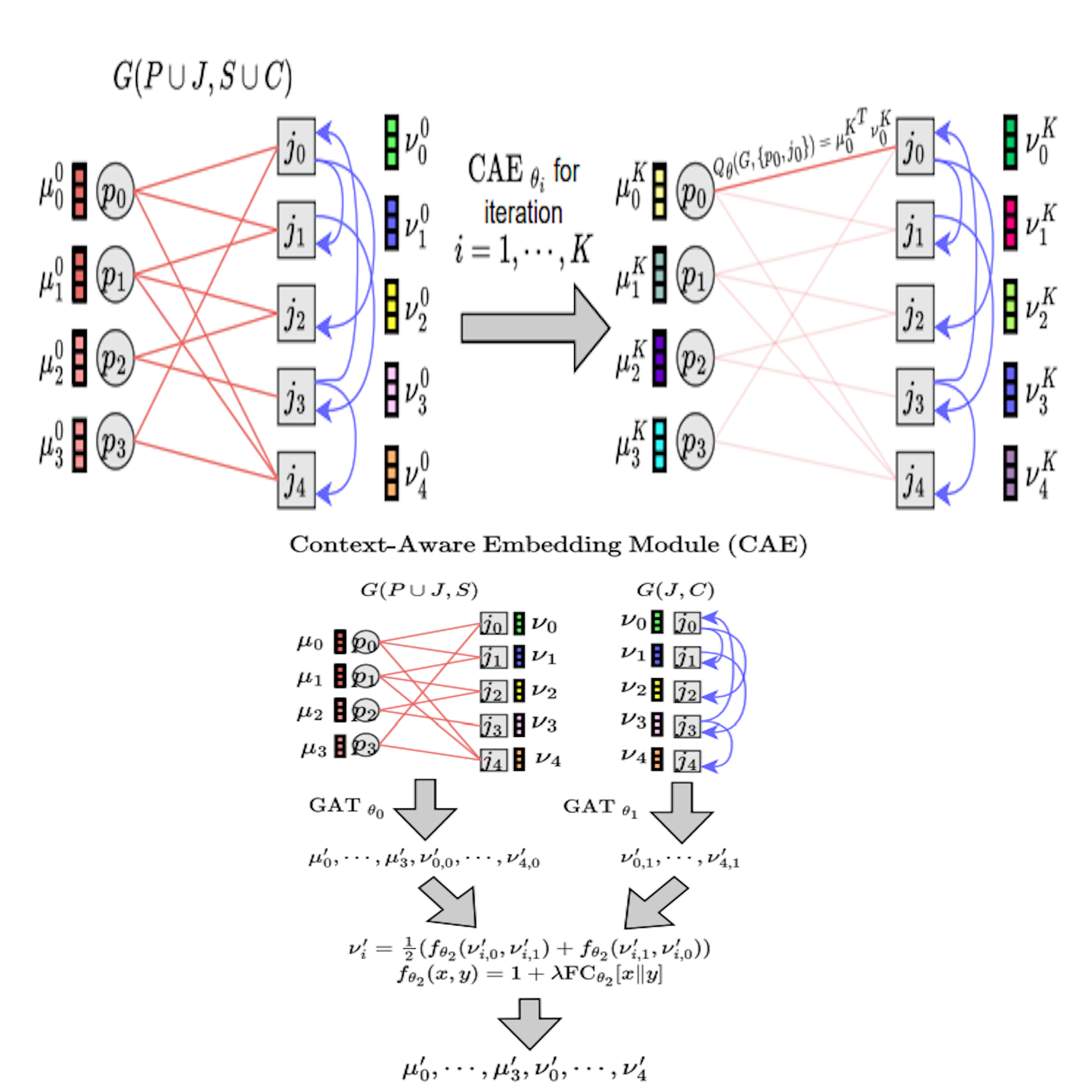
Raphael Boige * , Yannis Flet-Berliac * , Lars Quaedvlieg , Arthur Flajolet , Guillaume Richard , Thomas Pierrot
Reinforcement Learning Journal · 2024
* equal contribution

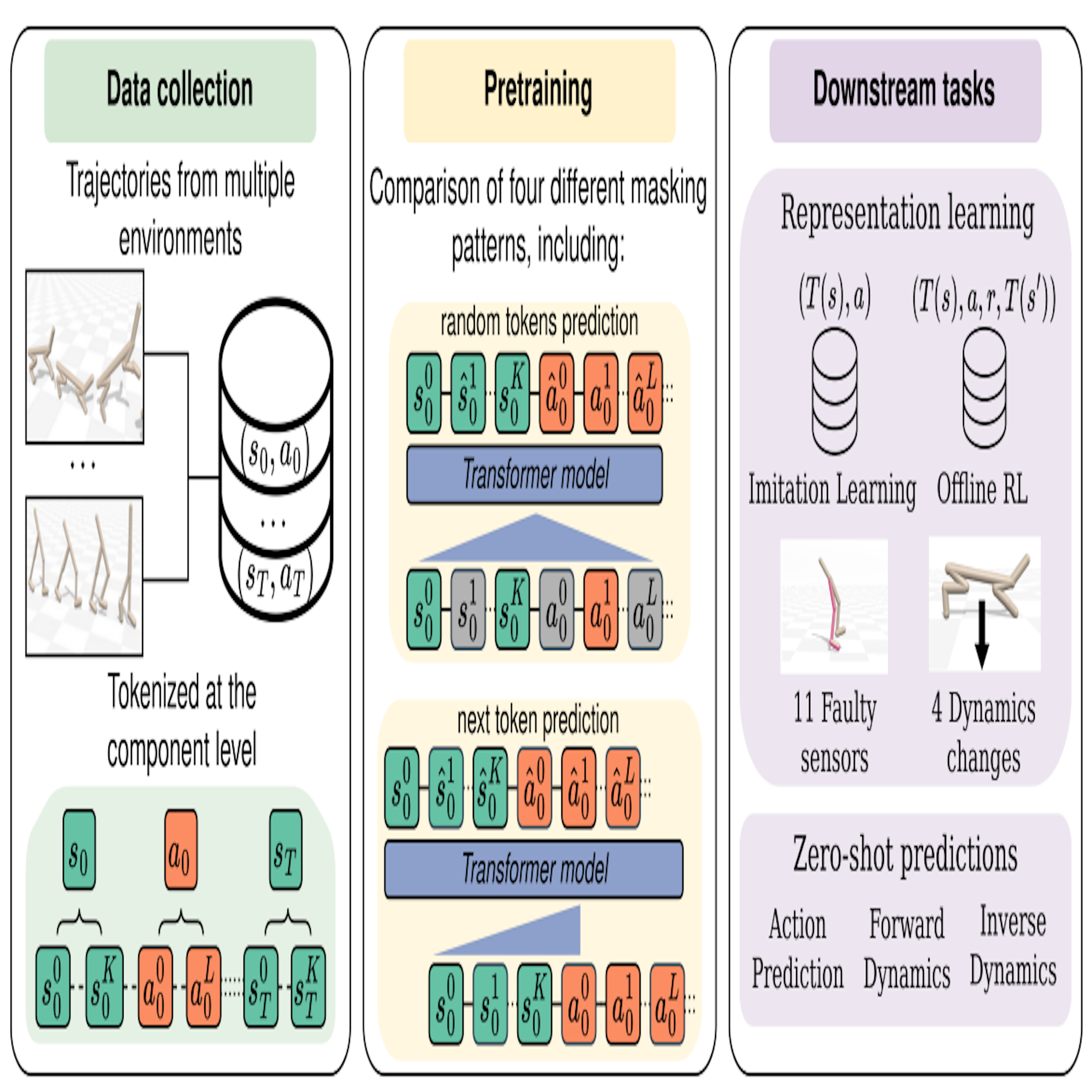
Lars Quaedvlieg * , L. Brusca * , S. Skoulakis , G. Chrysos , V. Cevher
Advances in Neural Information Processing Systems (NeurIPS) · 2023
* equal contribution

Lars Quaedvlieg
Bachelor's Thesis · 2022