Autonomous Lane Changing using Deep Reinforcement Learning with Graph Neural Networks
The aim of this project is to use advanced machine learning methods to solve problems within autonomous driving
This ML4Science project was completed for the CS-433 Machine Learning course taught at EPFL in Fall 2022. We are generously hosted by Volvo Group Trucks Technology and Chalmers University of Technology to work on this project.
In recent years, autonomous vehicles have garnered significant attention due to their potential to improve the safety, efficiency, and accessibility of transportation. One important aspect of autonomous driving is the ability to make lane-changing decisions, which requires the vehicle to predict the intentions and behaviors of other road users and to evaluate the safety and feasibility of different actions.
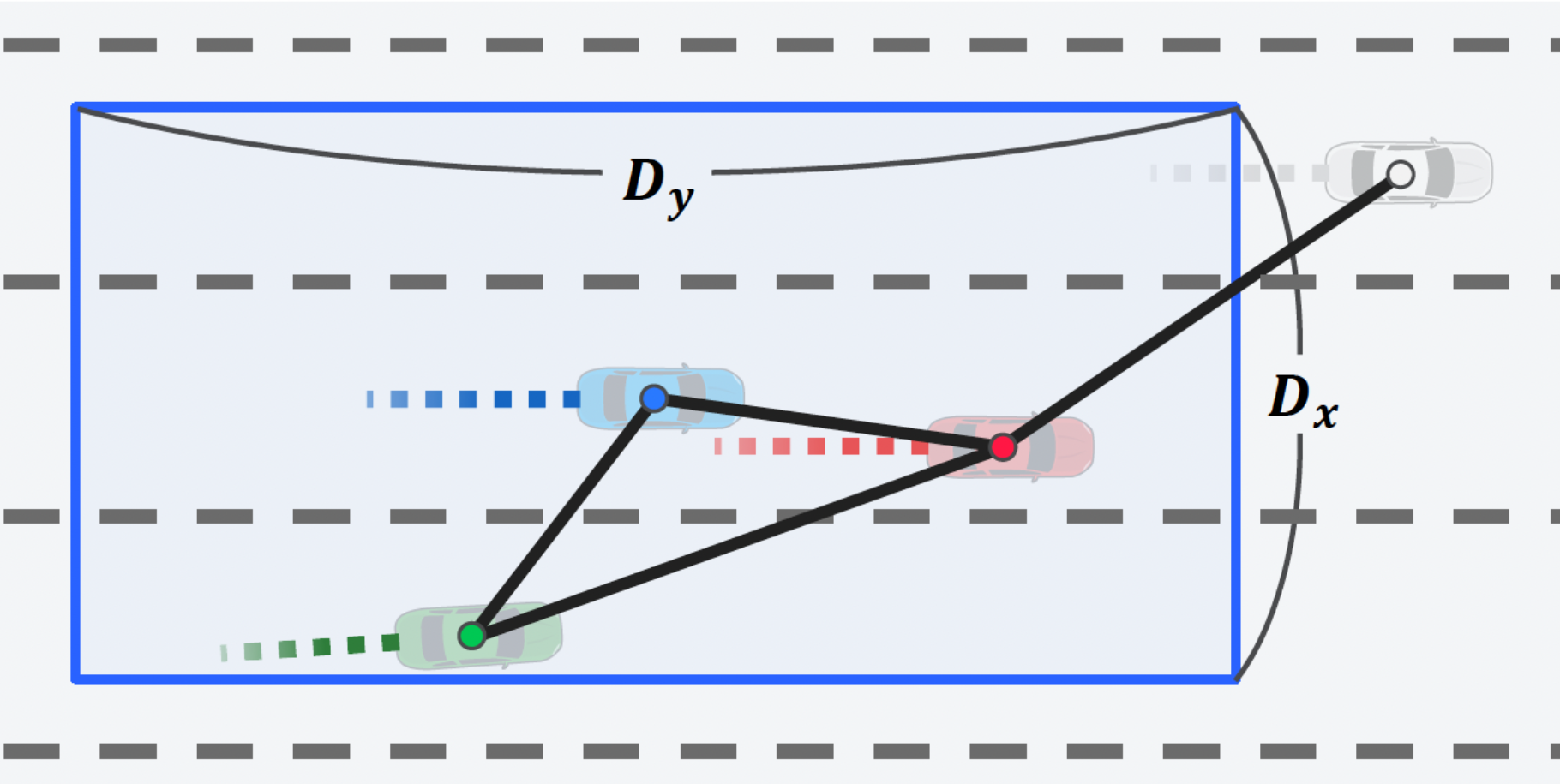
In this project, we propose a graph neural network (GNN) architecture combined with reinforcement learning (RL) and a model predictive controller to solve the problem of autonomous lane changing. By using GNNs, it is possible to learn a control policy that takes into account the complex and dynamic relationships between the vehicles, rather than just considering local features or patterns. More specifically, we employ Deep Q-learning with Graph Attention Networks for the agent.
The final report for this project is embedded below. It focuses on the most important points but does not exhaustively cover everything done in the project. For more information on the project implementations, visit the GitHub repository linked above.
Here are some keypoint of the project:
- Autonomous Lane Changing
- Deep Q-Learning
- Dynamic Graph Attention Networks
- Model Predictive Controller
The main finding from this project is that overall we have demonstrated the potential usage of deep RL with GNNs for automating lane-changing decisions. Thus, further training the model for more episodes could likely improve performance. However, we also noticed a strong bias in the algorithm towards certain actions, likely because the traditional experience replay mechanism tend to learn bias from imbalanced data. Improving the model architecture and environment will likely lead to better agents.