Optimizing Job Allocation using Reinforcement Learning with Graph Neural Networks
This project uses reinforcement learning and graph neural networks to schedule job assignments.
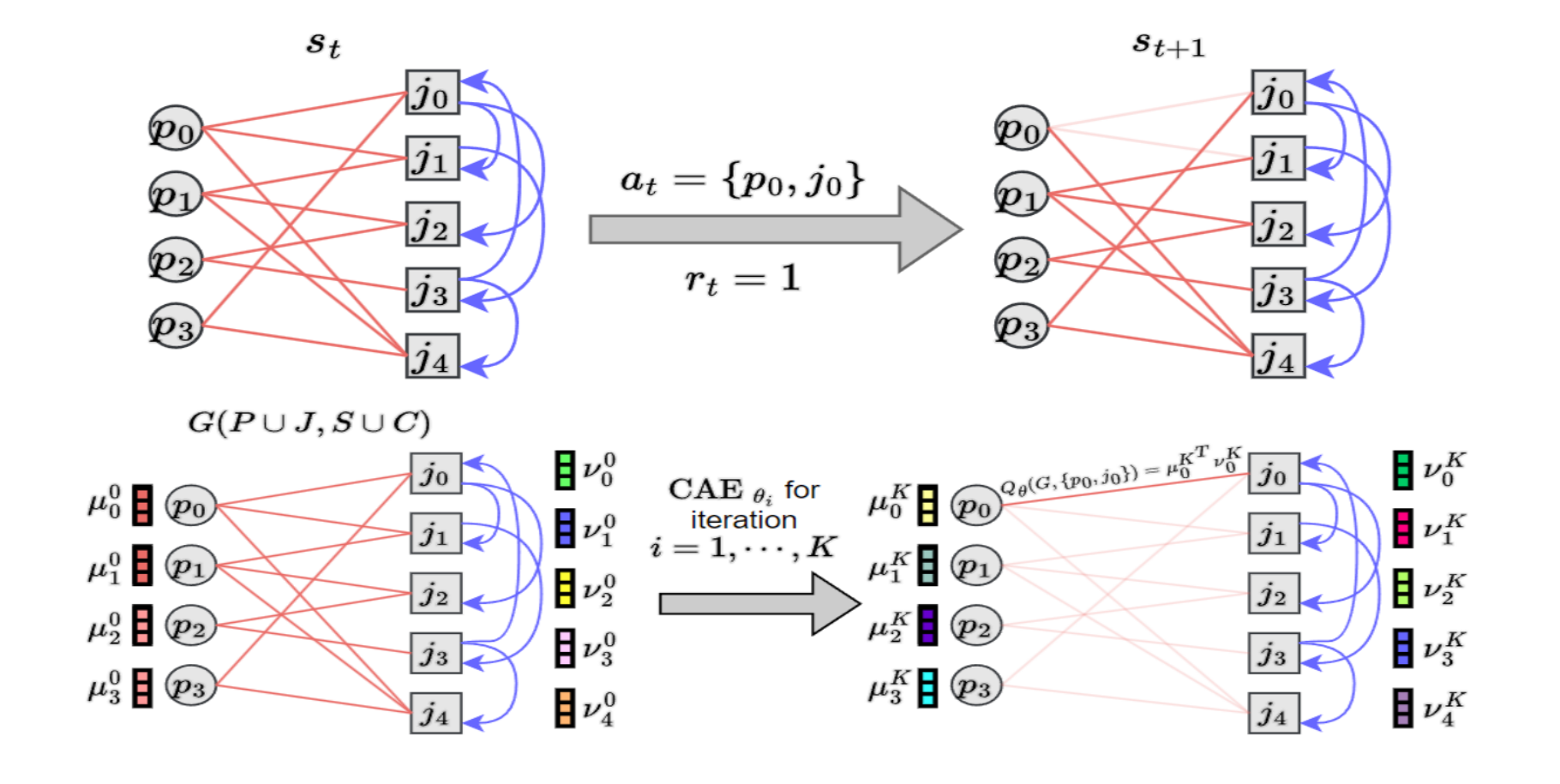
I am happy to share that, for this research project, I joined the Laboratory for Information and Inference Systems during the Spring 2023 semester. My work, supervised by Grigorios Chrysos and Stratis Skoulakis, is on the use of graph neural networks and reinforcement learning for scheduling problems. More specifically, we will focus on a job assignment problem for hospitals.
Efficient job allocation is a critical factor in various domains such as healthcare, logistics, and manufacturing, as it optimizes resource utilization and ensures timely task completion. This report introduces and investigates the Job Allocation Problem (JAP), which involves assigning a maximum number of jobs to available resources while considering multiple constraints.
The contributions of this project are twofold. Firstly, it showcases the effectiveness of Reinforcement Learning (RL) in overcoming the challenges posed by annotated data requirements, providing a practical and scalable approach to job allocation. By directly learning from simulations, the model demonstrates the ability to allocate jobs effectively without extensive manual labeling, thus enhancing efficiency.
Secondly, the utilization of GNNs allows the model to leverage the inherent graph structure of the JAP. This approach builds upon previous research where GNNs have shown promising results in solving combinatorial optimization problems.
Experimental evaluations conducted on both real-world and synthetic datasets validate the effectiveness of the proposed approach. The model’s superior performance over baseline algorithms highlights its potential for enhancing job allocation in various domains. Furthermore, out-of-distribution testing reveals the model’s generalizability, showcasing its ability to handle diverse scenarios beyond the training data.
The final report has been embedded below. It goes into detail about the problem, our approach, other related research, and experiments.